Unicorn Vs. Puma: Redux
UPDATE: The benchmarks have been updated for new versions of ruby, jruby, puma and unicorn
Previously I wrote about the difference in performance between using thin, puma and unicorn on heroku’s cedar stack. At the time, heroku’s recommendations where to use thin as a server. They now recommend unicorn for better performance and concurrency.
Additionally, I received some very valid criticism on the previous benchmark: Puma is designed to be used on a ruby implementation that does not have a Global Interpreter Lock: Namely Rubinius or jRuby. With that in mind, I decided to test again.
Methodology
Changing the ruby implementation requires much more effort than just changing the application server that heroku spins up. In fact, I could not get the small application I created for testing deployed on heroku using jruby at all. It seems that the auto-detection somehow fails for Rails 4.0.0rc1. In any case, this time around I decided to test locally, so that the network latency does not obscure the results.
The application to test is just a simple blog, with one model representing articles and 10 entries in the database. The endpoint under test is the index page that renders those 10 items from the database using rails provided scaffolding, running in production mode.
For the unicorn test, I used ruby 1.9.3-p392 and unicorn configured for 3 workers. I chose 3 workers, because that is the maximum number of workers that would not exceed the 512Mb of RAM available in a 1X heroku worker. The peak RAM utilization was 496Mb.
For the puma test, I used jRuby 1.7.3 (in 1.9 mode) with the default configuration, which by default uses a pool of up to 16 threads to respond to requests. The peak RAM utilization was 405Mb.
For the actual tests, after some server warm-up, I used siege to run 30 seconds of as much traffic as the server could handle, with varying levels of concurrent users issuing requests.
siege -b -c$USER_COUNT -t30s $URL
Results
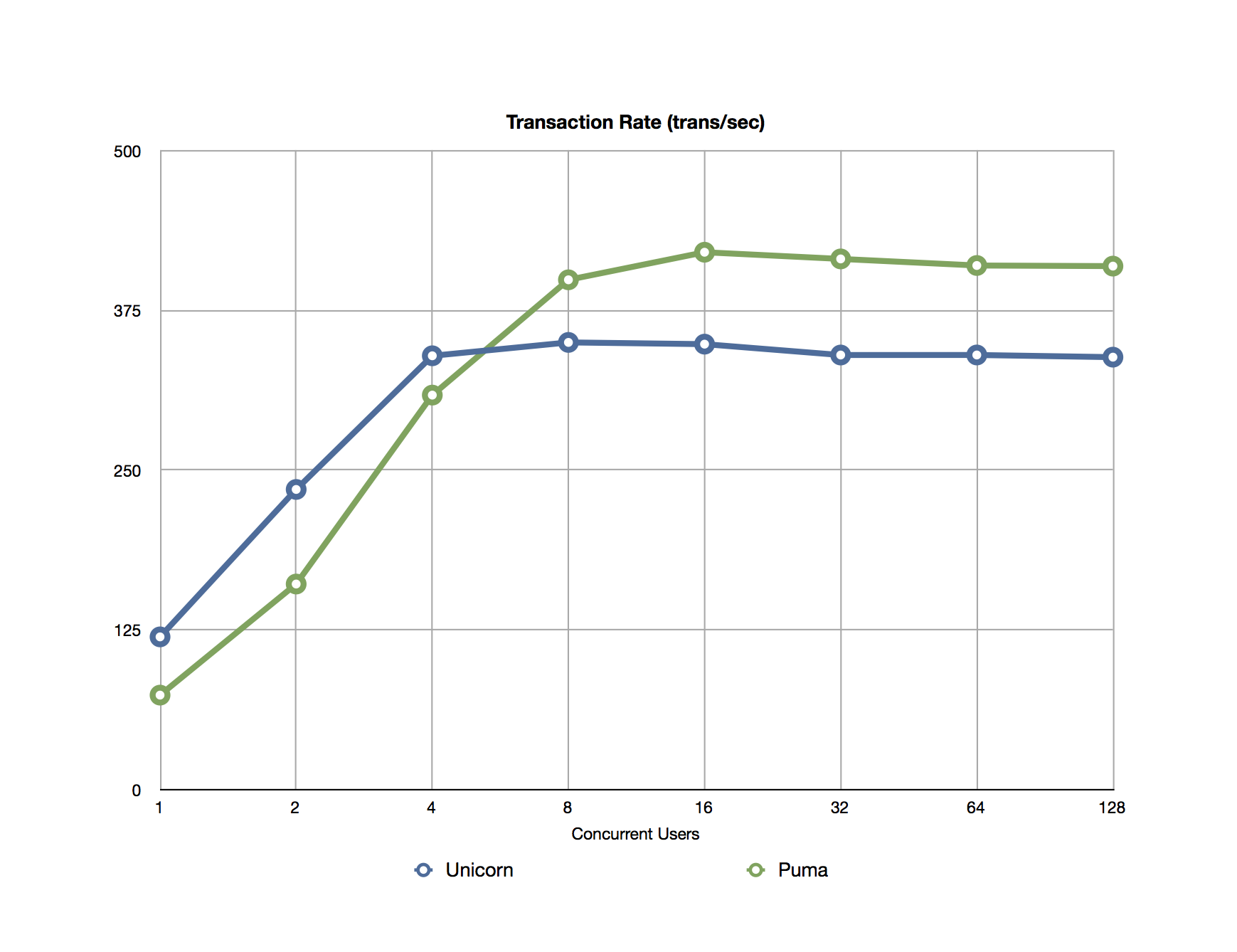
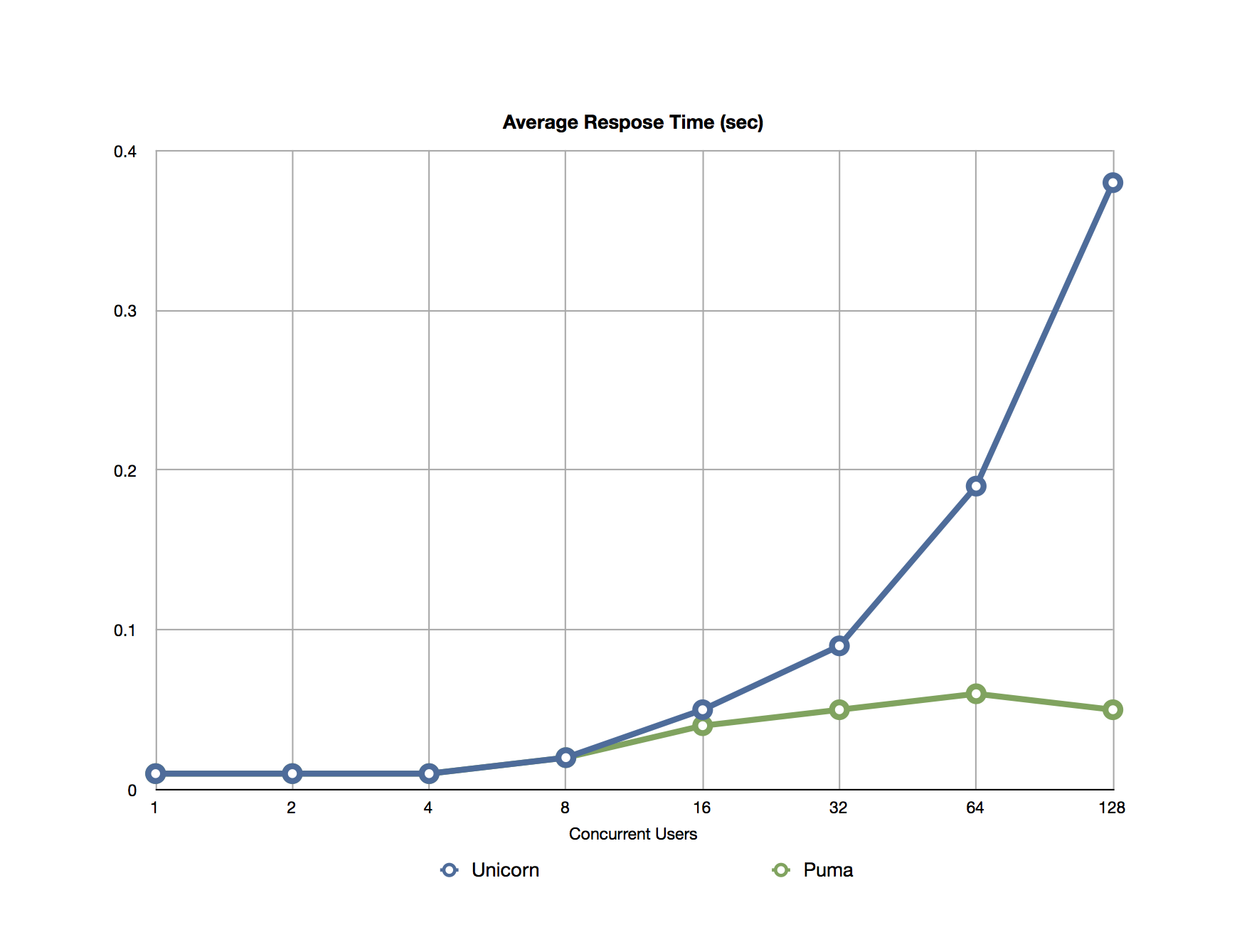
To compare the peformance, I focused on to metrics: Transaction Rate or Throughput (number of transactions per second) and Average Response Time graphed as follows:
Conclusions
The first graph shows both servers hitting their maximum transaction rate near 16 concurrent users. Puma tops out near 420 transactions/sec, while unicorn’s maximum is 350 transaction/sec.
The average response time though, tells a much more compelling story. Both server seem to handle low concurrency equally well, with response times of less than 20 milliseconds. However, unicorn’s performance quickly deteriorates and reaches almost 400 milliseconds when fully loaded with 128 concurrent users. On the other hand, puma’s performance is much steadier. It does reach 50 milliseconds, but that is almost an order of magnitude better than unicorn.
What does this mean? I wouldn’t jump to the conclusion that puma is always better than unicorn, but it’s performance was much better than I anticipated. At this point, I can’t tell if the performance comes from the server’s design or form leveraging the Java Virtual Machine threading. Regardless, I think that when it comes to squeezing the best performance from your hardware (or heroku’s for that matter), puma on jRuby is certainly a contender.
Find me on:
- Bluesky at @ylan.segal.family.com
- Mastodon at @ylansegal@mastodon.sdf.org
- By email at
ylan@{this top domain}