-
Conditionally setting your gitconfig, or not
In Conditionally setting your gitconfig, Marcus Crane solves a problem that many of us have: Different
gitconfiguration for personal and work projects. His solution includes adding conditional configuration, like so:[includeIf "gitdir:~/work/"] path = ~/.work.gitconfigI’ve been taking a different approach. According to the git-scm configuration page,
gitlooks for system configuration first, the the user’s personal configuration (~/.gitconfigor~/.config/git/config), and then the project’s specific configuration.In my personal configuration, I typically set my name, but don’t set my email.
[user] name = Ylan SegalOn first interaction with a repository,
gitmakes it evident that an email is needed:$ git commit Author identity unknown *** Please tell me who you are. Run git config --global user.email "you@example.com" git config --global user.name "Your Name" to set your account's default identity. Omit --global to set the identity only in this repository. fatal: no email was given and auto-detection is disabledI then use
git config user.email "ylan@...."to set a project-specific email. I don’t use the--globaloption. I want to make that choice each time I start interacting with a new repo.As they say, there are many ways to skin a cat.
-
The REPL: Issue 86 - October 2021
Bitcoin is a Ponzi
I’ve been thinking about this a lot: Bitcoin (and other crypto) seem like a Ponzi scheme. Is it? Jorge Stolfi make the argument that it is, and I find it compelling.
Understanding How Facebook Disappeared from the Internet
Interesting explanation of how BGP and DNS work, and how it it possible for a company like Facebook disappeared completely off the internet, and what it looked like for Cloudflare, one of the biggest content-delivery networks on the internet.
We Tried Baseball and It Didn’t Work
An allegory? Sarcasm? Humorous pastiche? You decide.
I call it satire. Like most funny ones, it resonates because it has a kernel of truth, exaggerated to absurdity. Squarely aimed at those that criticize Agile, TDD, or any other discipline without actually understanding it.
-
The Bike Shed Podcast Feedback
I recently listened to the The Bikshed, Episode 313 and sent some feedback for the hosts:
Hello Chris & Steph! I am a long-time listener of the podcast. Thank you for taking the time each week to record it.
On The Bikshed, Episode 313 you discussed a failure mode in which a Sidekiq job is enqueued inside a transaction. The job gets processed before the transaction commits, so the job encounters an unexpected database state. The job eventually succeeds when retried after the transaction commits.
The proposed solution, is to enqueue the job after the transaction commits. This certainly fixes that particular failure mode. It also makes possible different ones. Imagine the transaction commits, but the Sidekiq job can not be enqueued for whatever reason (e.g. network partition, buggy code, server node’s process runs out of memory). In this instance, you will fail to process your order. Is this better? You might not even notice that no job was enqueued. You can add code to check for that condition, of course.
In the original configuration, there are other failure modes as well. For example, the write to the database succeeds, the job enqueues, but then the transaction fails to commit (for whatever reason). Then you have a job that won’t succeed on retries. To analyze all failure modes, you need to assume that any leg of the network communication can fail.
The main problem you are running up against is that you trying to write to two databases (Postgres and Redis) in a single conceptual transaction. This is known as the “Dual Write” problem. Welcome to distributed systems. You can read a more thorough explanation by Thorben Janssen.
The approach outlined in that article – embracing async communication – is one way to solve the issue. For smaller Rails apps, there is another approach: Don’t use two databases! If you use a Postgres-based queue like GoodJob or even DelayedJob you don’t have this problem: Enqueuing the job is transactional, meaning that either everything writes (the records and the job) or nothing does: That is a very powerful guarantee. I try to hold on to it as much as possible.
I hope you’ve found this helpful.
Thanks again for the podcast.
-
The REPL: Issue 85 - September 2021
Understanding AWK
awkis powerful, and standard on all unix flavors. Its syntax is not immediately obvious. Adam Gordon Bell wrote an excellent tutorial on how to get started and write increasingly usefulawkprograms. I particularly found the summary boxes with “What I learned” at the end of each section. They serve to cement the knowledge, and quick reference when coming back to the tutorial later.How We Got to LiveView
Chris McCord, maintainer of Elixir’s Phoenix framework explains how LiveView came to be, and why it leans on the features of the BEAM (which powers Elixir). I am continue to be excited about the feature for Elixir and Phoenix.
The Two Types of Knowledge: The Max Planck/Chauffeur Test
The anecdote in this post is cute. It is funny because the chauffeur is quick-witted. The point is that real understanding about a topic, is more than just knowing the words, or memorizing some of the tenets.
True experts recognize the limits of what they know and what they do not know. If they find themselves outside their circle of competence, they keep quiet or simply say, “I don’t know.”
-
Leaning on ActiveRecord Relations for Query Optimization
I previously wrote about using views to create abstractions in Rails. As it happens, one of the queries using that view had some performance issues.
The offending query was generated by the following code:
SignatureRequirement .joins( missing_signatures: {participant: :households}, programs: {program_participants: {participant: :households}} ) .merge(household.people) .distinctSee the original post for an ERD diagram of the models involved.
The
EXPLAIN ANALYZEfor the generated query reported:Planning Time: 28.302 ms Execution Time: 9321.261 msThe
EXPLAIN ANALYZEoutput has a lot of information, and the noise can easily drown the signal. The excellent explain.depesz.com provides a way to visualize the output and color code the important information, to guide the discovery.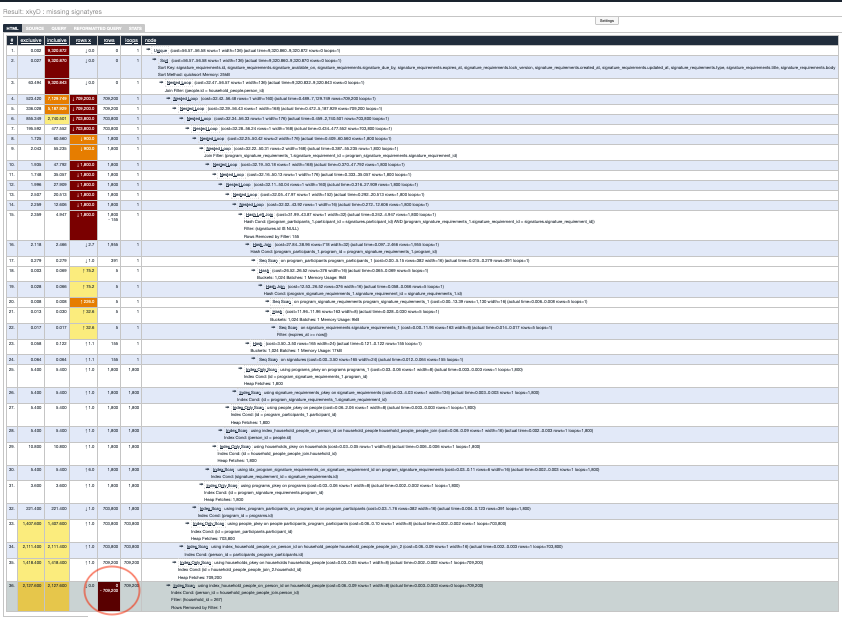
The proceeding image is too small to discern. At a glance though, its stands out (to me at least) that there is a lonely cell in dark colors at the bottom. The dark cell is for number of rows, and it contains 709,200 rows. I found that surprising. I know the system contains about 400 program participants and 5 signature requirements. Without any filtering, I expect the missing signatures view to return at most ~2,000 rows. Where are 700K rows coming from?
Cartesian Product
Wikipedia defines a Cartesion Product as:
In mathematics, specifically set theory, the Cartesian product of two sets A and B, denoted A × B is the set of all ordered pairs (a, b) where a is in A and b is in B.
A cartesian product represents all the possible combinations of members from two different sets. It comes into play in databases, when a query is constructed in such a way that it returns all possible combinations of multiple tables, potentially returning many rows.
As an example, lets assume we have two tables with the following data:
SELECT * FROM people; -- id -- ---------- -- 1 SELECT * FROM colors; -- person_id name -- ---------- ---------- -- 1 red -- 1 blue -- 1 white SELECT * FROM flavors; -- person_id name -- ---------- ---------- -- 1 chocolate -- 1 vanilla -- 1 strawberryA cartesian product combines all possible combinations (3 X 3 = 9):
SELECT people.id, colors.name, flavors.name FROM people JOIN colors ON people.id = colors.person_id JOIN flavors ON people.id = flavors.person_id; -- id name name -- ---------- ---------- ---------- -- 1 blue chocolate -- 1 blue strawberry -- 1 blue vanilla -- 1 red chocolate -- 1 red strawberry -- 1 red vanilla -- 1 white chocolate -- 1 white strawberry -- 1 white vanillaMy hunch was that a cartesian product was being generated by unnecessary joins.
Query Optimization
Luckily, the query to optimize has a very good test suite around it, ensuring that the data returned is correctly scoped and de-duplicated. That gave me confidence to aggressively refactor.
SignatureRequirement .joins( missing_signatures: {participant: :households}, programs: {program_participants: {participant: :households}} ) .merge(household.people) .distinctThe original code is trying to find signature requirements that have missing signatures for members of a household. Inspecting the generated SQL reveals 11 joins, not counting the underlying joins in the
missing_signaturesview.After taking a step back, I noticed that the code I really wanted to write was:
household.missing_signature_requirements.distinctAfter realizing that, it became obvious that
has_manywith itsthroughoptions should be more than equal to the task. Here are the associations that make that code possible:class Household < ApplicationRecord has_many :household_people has_many :people, through: :household_people has_many :missing_signature_requirements, through: :people end class HouseholdPerson < ApplicationRecord belongs_to :household belongs_to :person end class Person < ApplicationRecord has_many :missing_signatures, inverse_of: :participant, foreign_key: :participant_id has_many :missing_signature_requirements, through: :missing_signatures, source: :signature_requirement end class MissingSignature < ApplicationRecord belongs_to :signature_requirement belongs_to :participant, class_name: "Person" end class SignatureRequirement < ApplicationRecord has_many :missing_signatures endThe new query generates only 3 joins, and looks like this:
SELECT DISTINCT "signature_requirements".* FROM "signature_requirements" INNER JOIN "missing_signatures" ON "signature_requirements"."id" = "missing_signatures"."signature_requirement_id" INNER JOIN "people" ON "missing_signatures"."participant_id" = "people"."id" INNER JOIN "household_people" ON "people"."id" = "household_people"."person_id" WHERE "household_people"."household_id" = 267Results
The resulting query is more legible, and more importantly more performant. Here is the bottom line from
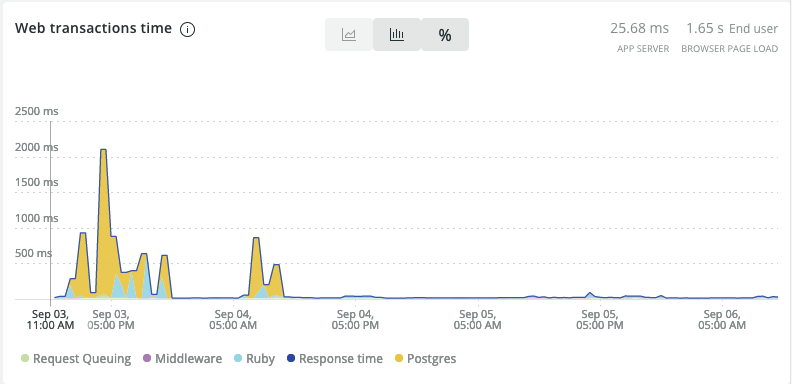
EXPLAIN ANALYZE:Before: Planning Time: 28.302 ms Execution Time: 9321.261 ms After: Planning Time: 2.716 ms Execution Time: 23.580 msThe new query is less than 1% of the original query. The New Relic dashboard shows the performance improvement: