Leaning on ActiveRecord Relations for Query Optimization
I previously wrote about using views to create abstractions in Rails. As it happens, one of the queries using that view had some performance issues.
The offending query was generated by the following code:
SignatureRequirement
.joins(
missing_signatures: {participant: :households},
programs: {program_participants: {participant: :households}}
)
.merge(household.people)
.distinct
See the original post for an ERD diagram of the models involved.
The EXPLAIN ANALYZE for the generated query reported:
Planning Time: 28.302 ms
Execution Time: 9321.261 ms
The EXPLAIN ANALYZE output has a lot of information, and the noise can easily drown the signal. The excellent explain.depesz.com provides a way to visualize the output and color code the important information, to guide the discovery.
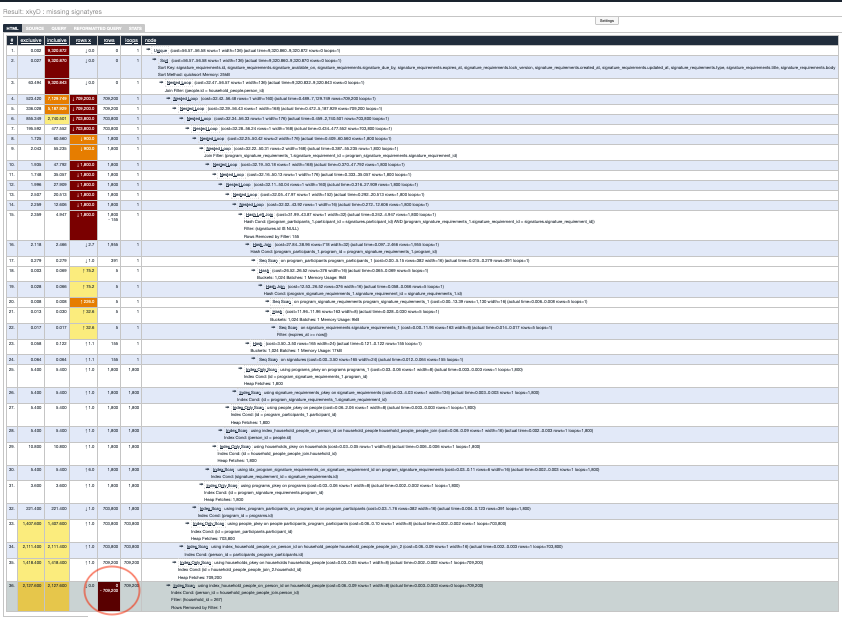
The proceeding image is too small to discern. At a glance though, its stands out (to me at least) that there is a lonely cell in dark colors at the bottom. The dark cell is for number of rows, and it contains 709,200 rows. I found that surprising. I know the system contains about 400 program participants and 5 signature requirements. Without any filtering, I expect the missing signatures view to return at most ~2,000 rows. Where are 700K rows coming from?
Cartesian Product
Wikipedia defines a Cartesion Product as:
In mathematics, specifically set theory, the Cartesian product of two sets A and B, denoted A × B is the set of all ordered pairs (a, b) where a is in A and b is in B.
A cartesian product represents all the possible combinations of members from two different sets. It comes into play in databases, when a query is constructed in such a way that it returns all possible combinations of multiple tables, potentially returning many rows.
As an example, lets assume we have two tables with the following data:
SELECT * FROM people;
-- id
-- ----------
-- 1
SELECT * FROM colors;
-- person_id name
-- ---------- ----------
-- 1 red
-- 1 blue
-- 1 white
SELECT * FROM flavors;
-- person_id name
-- ---------- ----------
-- 1 chocolate
-- 1 vanilla
-- 1 strawberry
A cartesian product combines all possible combinations (3 X 3 = 9):
SELECT
people.id,
colors.name,
flavors.name
FROM
people
JOIN colors ON people.id = colors.person_id
JOIN flavors ON people.id = flavors.person_id;
-- id name name
-- ---------- ---------- ----------
-- 1 blue chocolate
-- 1 blue strawberry
-- 1 blue vanilla
-- 1 red chocolate
-- 1 red strawberry
-- 1 red vanilla
-- 1 white chocolate
-- 1 white strawberry
-- 1 white vanilla
My hunch was that a cartesian product was being generated by unnecessary joins.
Query Optimization
Luckily, the query to optimize has a very good test suite around it, ensuring that the data returned is correctly scoped and de-duplicated. That gave me confidence to aggressively refactor.
SignatureRequirement
.joins(
missing_signatures: {participant: :households},
programs: {program_participants: {participant: :households}}
)
.merge(household.people)
.distinct
The original code is trying to find signature requirements that have missing signatures for members of a household. Inspecting the generated SQL reveals 11 joins, not counting the underlying joins in the missing_signatures view.
After taking a step back, I noticed that the code I really wanted to write was:
household.missing_signature_requirements.distinct
After realizing that, it became obvious that has_many with its through options should be more than equal to the task. Here are the associations that make that code possible:
class Household < ApplicationRecord
has_many :household_people
has_many :people, through: :household_people
has_many :missing_signature_requirements, through: :people
end
class HouseholdPerson < ApplicationRecord
belongs_to :household
belongs_to :person
end
class Person < ApplicationRecord
has_many :missing_signatures, inverse_of: :participant, foreign_key: :participant_id
has_many :missing_signature_requirements, through: :missing_signatures, source: :signature_requirement
end
class MissingSignature < ApplicationRecord
belongs_to :signature_requirement
belongs_to :participant, class_name: "Person"
end
class SignatureRequirement < ApplicationRecord
has_many :missing_signatures
end
The new query generates only 3 joins, and looks like this:
SELECT DISTINCT
"signature_requirements".*
FROM
"signature_requirements"
INNER JOIN "missing_signatures" ON "signature_requirements"."id" = "missing_signatures"."signature_requirement_id"
INNER JOIN "people" ON "missing_signatures"."participant_id" = "people"."id"
INNER JOIN "household_people" ON "people"."id" = "household_people"."person_id"
WHERE
"household_people"."household_id" = 267
Results
The resulting query is more legible, and more importantly more performant. Here is the bottom line from EXPLAIN ANALYZE:
Before:
Planning Time: 28.302 ms
Execution Time: 9321.261 ms
After:
Planning Time: 2.716 ms
Execution Time: 23.580 ms
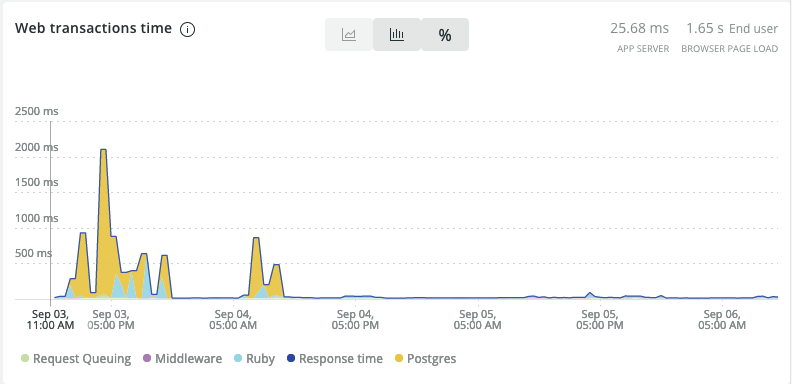
The new query is less than 1% of the original query. The New Relic dashboard shows the performance improvement:
Find me on:
- Bluesky at @ylan.segal.family.com
- Mastodon at @ylansegal@mastodon.sdf.org
- By email at
ylan@{this top domain}